
The GenBank database at the NCBI is a popular web-based research utility. It comprises various annotation data, e.g. biblographic data, sequence localizations, DNA and RNA sequences as well as protein sequences, for many genomic regions of various genomes. Each entry is identified by a unique accession id. Such annotation data can be used for any further purposes, e.g. sequence alignment to determine the secondary strucure or to build phylogentic trees.
Many analysis tasks can be performed using the web-based tools available at the NCBI or other related web-sites. On the other side there are many stand-alone tools such as ClustalW, which run on local computers and are not web-based. These tools makes it necessary to download and store the data from the GenBank database locally. But, many times the data has to prepared, e.g. subsequences has to be cut from the entire sequence, before it can be analyzed. In addition, a large number of GenBank data files which are used for the local analysis make a comprehensive GenBank entry management necessary.
For this purpose, we have designed a GenBank management system which imports, stores and manages all required GenBank entries in a local database. Figure 1 shows the user interface to search specific GenBank entries by using different filters. To find all entries with a similar filter condition, the wildcards "%" are supported. For example the filter "NC_%" shows all GenBank entries whose accession id starts with "NC_". In addition, it is possible to specify more than one filter value which should be separarted by comma. These filter values are combined in the database query processing with a logical "OR".
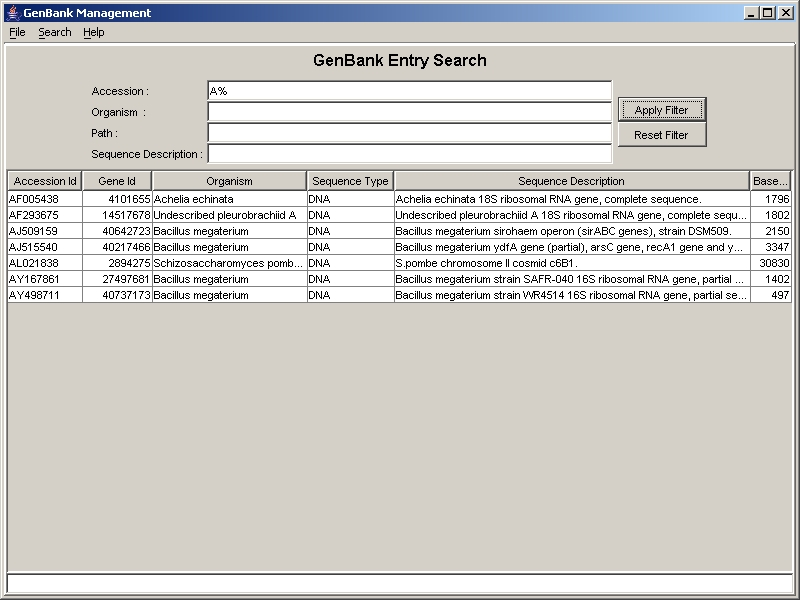
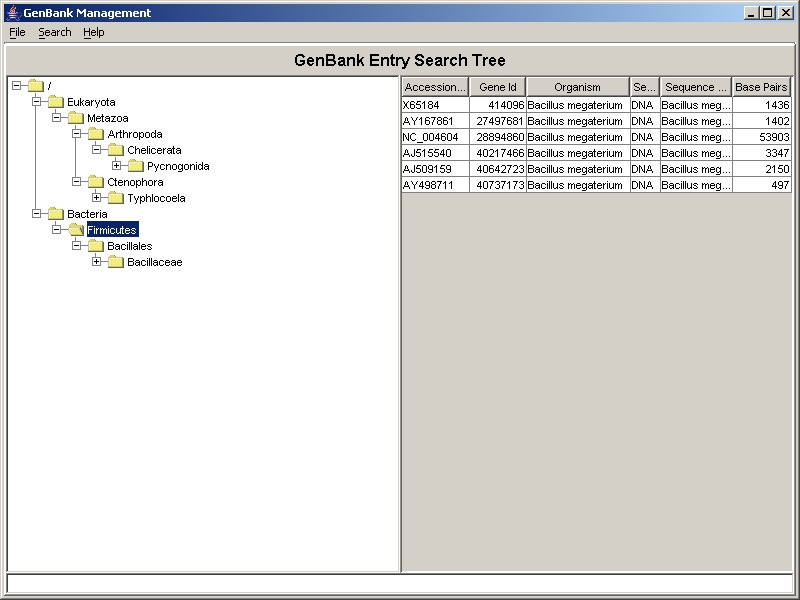
Figure 2 shows the tree of organism taxonomy (or the ontology) as included in the GenBank file. By clicking on such a taxonomy node all corresponding GenBank entries are listed in the table next to it. While the root contains all local available entries, the leafs (last nodes on the right hand side) comprise only corresponding entries. Each table row represents a GenBank entry. The entries can be marked by using the left mouse button. The multiple selection is made by pressing Shift and Ctrl buttons on the keyboard additionally. Using the context menu by pressing the right mouse button, lets export entire sequences, feature sequences and translations, i.e. protein sequences, of the marked entries. Then, an export file is created for each marked GenBank entry. The export format is fasta-like.
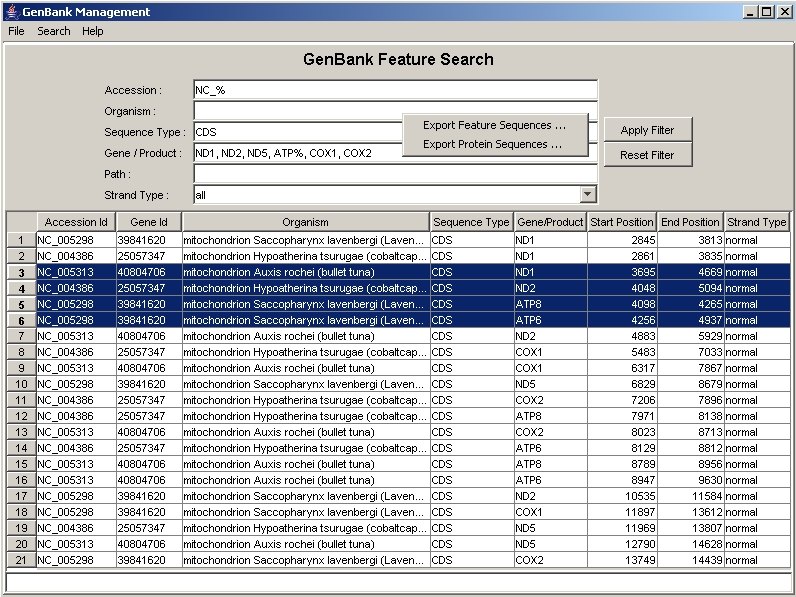
In addition, the program lists all available features in tabular form as shown in Figure 3. Equivalent to the GenBank entry table the rows can be sorted by a mouse click on the columns title of the table. The filters can be used to select specific entries and to reduce the listed features, of course. Features of interest can be marked using the mouse button (also together with Ctrl/Shift). The sequences (DNA/RNA/Protein) then can be exported to file in fasta format. All sequences which are marked as complement sequences in the GenBank file are exported in the re-complementary form.
The main functionalities of the program are:
The program is fully written in Java using the biojava package.
We hope this program is useful for local GenBank entry data management. Please, let us know, if you have any questions or recommendations to improve this program in the future.
The download (Version 0.5 - 01.03.2004) includes all necessary and additional files and packages.
Please use this download to get only the latest gbm package.
A short Readme should help you to install the tool.
We provide the source code on request.
Last modified: 01.03.2004 by Toralf Kirsten |

|